Why Modern Data Teams Are Rethinking Warehouse Costs with dbt Fusion


dbt (data build tool) is the secret weapon of modern data teams — the “T” in ELT: the transformation layer that turns raw data into something meaningful. Since 2016, dbt Core, the open-source engine, has been the backbone of this process, empowering teams to write modular SQL, version control transformations, and build reliable data pipelines.
But the world of data doesn’t stand still. Performance demands grow, complexity increases, and teams need more speed and flexibility. That’s where dbt Fusion comes in — a complete, ground-up rewrite of the engine in Rust, designed for the next generation of data workflows. Fusion isn’t just faster; it’s smarter, with native SQL comprehension that unlocks new possibilities for optimization and scalability.
Long story short
dbt Core started the revolution. dbt Fusion is taking it to the next level.
dbt Fusion reduces warehouse costs by up to 29%, accelerates development cycles by 30x, and catches errors before they cost you money.
If your organization runs dbt Core today, Fusion is the clearest upgrade path for measurable ROI. If you're evaluating data transformation tools, Fusion sets the new benchmark.
And this is not just an experience; we have some hard evidence. Here's what the numbers look like:

The recommendation is straightforward: start evaluating Fusion now. It's available in Preview, the VS Code extension is free, and early adopters are already reporting significant improvements in team velocity.
Let me show you why these numbers hold up.
You're paying for compute you don't need
Here's a scenario most data teams know too well: Your daily dbt job runs 200 models. But only 30% of your source tables have new data. With dbt Core, you rebuild everything anyway paying full compute costs for identical outputs.
This isn't a theoretical problem. It's the default behavior, and it's costing organizations real money every single day.
Fusion's state-aware orchestration changes this equation.
The engine tracks which sources have fresh data and skips models that would produce the same results. Think of it like this: if one of your tables hasn't changed since yesterday, why rebuild every downstream model that depends on it? Those queries would generate identical outputs, consuming warehouse credits for zero business value.
Fusion detects this automatically. (Yes, you can cobble together source freshness checks and custom orchestration in Core — but Fusion makes it native and zero-maintenance. In testing, dbt Labs documented specific, stackable savings:
- 10% savings from basic state-aware orchestration — simply knowing what's changed
- 15% additional savings with advanced configurations like updates_on and build_after— specifying exactly when models should rebuild based on freshness thresholds
- 4% additional savings from intelligent test optimization — aggregating multiple tests into single queries and skipping redundant tests when columns pass through unchanged
Combined: up to 29% reduction in deployment costs. Some early customers have seen over 50% total savings when all optimizations are applied.
Let's make this concrete. For a mid-sized organization spending $500K annually on Snowflake or BigQuery compute, 29% savings mean $145K back in the budget — recurring, every year. That's not a one-time gain; its permanent efficiency built into your infrastructure.

The feedback loop that's killing your team's productivity
dbt Core's Python-based architecture hasn't fundamentally changed since 2016. For projects with hundreds of models, parse times alone can stretch to several minutes. Then you wait for compilation. Then you wait for execution. Then — after all that waiting — you discover a typo in line 47.
Fix. Rebuild. Wait. Repeat.
This cycle isn't just frustrating — it's expensive in ways that don't show up on your cloud bill. Developer time is your most valuable resource, and every minute spent waiting is a minute not spent delivering insights to the business. Multiply across a team of five or ten engineers, across hundreds of daily iterations, and you're looking at substantial hidden costs.
GitHub issues from the dbt community have documented this pain over the years: engineers waiting several minutes just to compile a few hundred models.
Fusion, rewritten entirely in Rust, delivers 30x faster parsing.
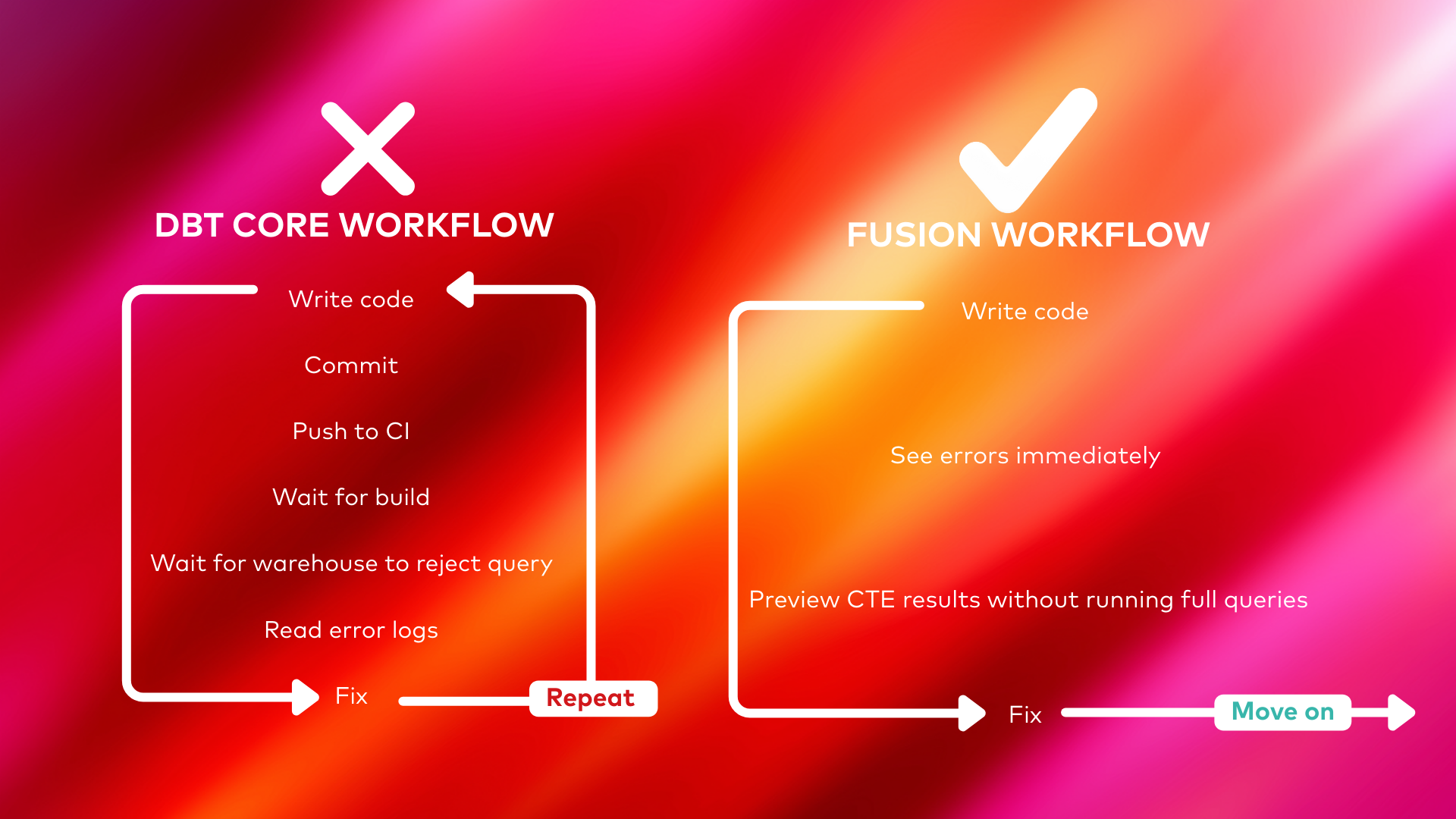
But raw speed alone isn't the breakthrough. The real transformation is when errors get caught. Consider the difference:
- dbt Core workflow: Write code → Commit → Push to CI → Wait for build → Wait for warehouse to reject query → Read error logs → Fix → Repeat entire cycle
- Fusion workflow: Write code → See errors immediately → Preview CTE results without running full queries → Fix → Move on
The VS Code extension powered by Fusion validates SQL in real-time as you type. Typos, invalid column references, type mismatches, incorrect function usage — all caught before you ever run a command. No warehouse costs are incurred. No pipeline to wait for.
As one data team lead described their pre-Fusion workflow: "Long feedback loops on CI, and an increased Snowflake bill." Fusion eliminates both problems simultaneously — faster development and lower costs.
Finally: An Engine That Actually Understands Your SQL
This is the architectural limitation that constrained everything else. dbt Core treats SQL as text to be templated and passed to the warehouse. It renders your Jinja macros into SQL strings, but it doesn't comprehend what those SQL statements mean. It can't tell you if a column exists, if a join makes sense, or if a function will work on your target platform.
Think of it like a mail carrier who delivers letters without reading them. The job gets done, but there's no intelligence about what's inside.
Fusion includes a full SQL compiler. It parses your queries, understands column relationships, validates data types, and tracks how data flows through your entire DAG — all before anything touches your warehouse.
This comprehension enables capabilities that were architecturally impossible before:
- Column-level lineage — See exactly where each column originates and what consumes it downstream. No more guessing or manually tracing through files.
- Impact analysis — Know instantly which models break when you change an upstream column. Fusion highlights all downstream dependencies affected by your changes.
- Automatic refactoring — Rename a column in one model, and Fusion updates all references across your entire project automatically. What used to be a risky, manual process becomes a one-click operation.
- Cross-platform validation — Switch your target warehouse in configuration, and Fusion immediately identifies which functions won't work on the new platform. Critical for multi-cloud strategies or migration planning.
For governance and compliance teams, column-level lineage is particularly valuable. When an auditor asks, "where does this revenue metric come from?", you can answer definitively in seconds — tracing the data from source systems through every transformation to the final dashboard. That's not just convenient; for regulated industries, it's essential.
This is also exactly what GenAI applications need. When an AI assistant queries your data — whether that's a chatbot answering business questions or an agent automating reports — it needs context. Where did this column come from? What transformations were applied? Is this metric trustworthy? Without this context, AI outputs are guesswork at best.
Fusion's SQL comprehension generates this rich metadata automatically. Your dbt project becomes a reliable foundation for AI-powered analytics rather than a black box that AI tools can't reason about. This is the bridge between traditional analytics engineering and the GenAI-driven future that organizations are racing toward.
Under the Hood: What Makes Fusion Different
You don't need to understand systems programming to grasp the key architectural choices:
Why Rust? dbt Core is written in Python — readable and flexible but not built for performance. Rust is a systems-level language designed for speed and memory safety. Fusion compiles to a single binary with no dependencies. No Python environment to manage, no Docker complexity, no version conflicts.
Why a SQL compiler? Traditional dbt templates your SQL and hands it off. Fusion parses the SQL, building a logical representation of your queries. This is what enables real-time validation, lineage tracking, and intelligent optimization. The engine uses Apache Arrow (industry-standard for in-memory data) and DataFusion (a query engine that understands SQL semantics across dialects).
What's "ahead-of-time" rendering? dbt Core processes models as they're about to run ("just-in-time"). Fusion analyzes your entire project upfront ("ahead-of-time"). If model #47 in your DAG has a syntax error, dbt Core discovers this after running models 1-46. Fusion catches it before running anything — saving you 46 models' worth of compute costs.
Fusion as the GenAI Enabler
The GenAI connection isn't a side benefit — it's central to why Fusion matters now. Three trends are converging that make this particularly timely:
1. Warehouse costs keep rising. As organizations mature their data practices, they're running more models, more frequently, on larger datasets. The bill grows accordingly. CFOs are asking harder questions about data ROI, and "we need more compute" isn't a satisfying answer. Efficiency gains — doing more with less — are becoming strategic priorities.
2. AI demands governed data. Large language models and AI applications are only as good as the data they're built on. But AI systems need more than raw data — they need context. Where did this metric come from? How was it calculated? What transformations were applied? Fusion's SQL comprehension and column-level lineage provide exactly this metadata foundation. Without it, AI outputs are untrustworthy at best, dangerous at worst.
3. Developer experience is a competitive advantage. Teams that ship faster win. In a tight labor market, the tools you provide your engineers affect both retention and productivity. Nobody wants to spend their day watching progress bars. The organizations that give their data teams modern, responsive tooling will attract better talent and deliver more value.
Fusion addresses all three trends simultaneously. The cost savings are documented and immediate. The SQL comprehension provides the rich metadata that AI applications need. And the developer experience — real-time feedback, instant lineage, automatic refactoring — is genuinely transformational for day-to-day work.
dbt Labs is already building on this foundation. They've launched the dbt MCP server (Model Context Protocol) for AI integrations, enabling tools like Claude and GPT to access governed data context. They've announced dbt Agents for development, discovery, and observability — AI assistants that understand your data stack. Fusion is the engine powering this entire next generation of capabilities.
Summary: What This Means for You
- 29% warehouse cost savings — Documented, achievable with state-aware orchestration and test optimization
- 30x faster development — Rust architecture plus real-time validation eliminates the compile-wait-fail cycle
- Errors caught before they cost money — SQL comprehension validates locally, before touching the warehouse
- GenAI-ready infrastructure — Column-level lineage and rich metadata enable trustworthy AI-powered analytics
Fusion is available today — no contracts required, no cost for the VS Code extension, and migration tooling handles most compatibility issues automatically.
The question isn't whether Fusion delivers value — the numbers are clear. The question is how quickly your team can capture it, and whether you'll be ready when GenAI becomes central to how your organization consumes data.
Interested in implementing dbt Fusion or exploring how it fits your data stack? Reach out to Datashift , we'd be happy to walk you through the technical details.
Keep reading
Eager to learn more? No worries: we’ve got you covered.
.png)
Data Products Need Funding. Not Projects.
Your data product strategy is not failing because of your technology. It is not failing because of your talent. It is hitting a wall because you are trying to run a product organisation on a project budget. These two models are fundamentally incompatible.


From Messy Documents to Governed Knowledge: What Our Hackathon Revealed About AI Agents
Most of an organization's knowledge lives outside structured systems: slide decks, meeting notes, contracts, feedback forms, and old project folders. This knowledge was the focus of a recent Datashift hackathon.

.png)
Centralized or Decentralized? Building a Silver Layer that does both with dbt
Most data teams are stuck choosing between consistency and speed: central control brings governance but creates bottlenecks, while domain ownership brings agility but leads to chaos. This blog explores a hybrid Silver layer that delivers both, using dbt as the framework to make it work.
.jpg)


