Centralized or Decentralized? Building a Silver Layer that does both with dbt
.jpg)

Inside every modern data platform, there are two forces: one striving for centralized governance and consistency, the other pushing toward decentralized ownership and agility. The benefits of both are highly desirable, but finding the right balance is the real challenge.
Decentralization is more often introduced at the Gold layer, where business-facing data products are created. But what if we take a step back and explore the possibility of achieving it already in the Silver layer, where raw data is transformed into trusted, analytics-ready datasets?
Rethinking the Silver layer
Effective design is not only a technical challenge, but also part of a broader organizational data strategy. Thankfully, flexible tools such as dbt provide a solid framework to support both governance and autonomy. Let’s explore how this can be achieved.
First, let’s think about what the Silver layer should bring to the table. In the medallion architecture, sitting between Bronze - raw, ingested data - and Gold - business-facing, polished data models - the Silver layer is where data is cleaned, standardized, and deduplicated. It’s all about data quality: rules and tests are enforced, schemas become more stable, and business logic starts to take shape. Because of this, it becomes a vital point of control, but also a source of disputes regarding access and ownership.
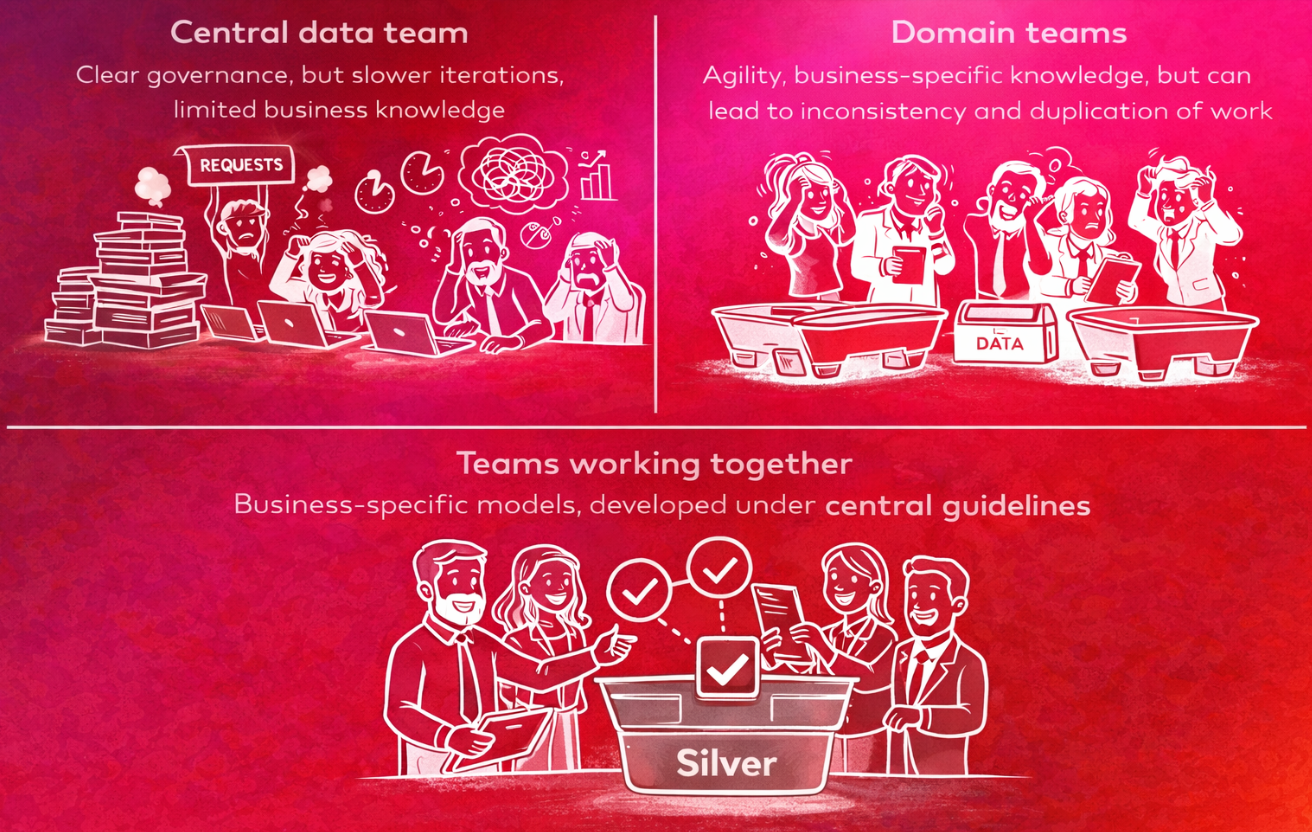
Both directions have strong arguments. Centralization, understood as a main data team owning the Silver layer, usually brings consistency in definitions, clear governance, easier compliance, and avoidance of duplicated work. On the other hand, there are disadvantages: bottlenecks, slower iterations, and limited domain expertise.
Decentralization (where domain teams such as marketing or finance own their transformations) is tempting with its speed, agility, domain-specific accuracy, and promise of accountability. The trade-off, however, can be costly: logic duplication, inconsistent definitions, and never-ending efforts to align metrics across domains. Is there a good way out of this dilemma?
The Hybrid Model in Action (Powered by dbt)
The key is to shift thinking away from choosing one over the other and instead aim to get the best of both worlds through close collaboration. A hybrid approach could focus on:
1. Centralized core models
2. Decentralized domain models
3. Clear contracts and communication between layers
To support this kind of hybrid design in practice, let’s briefly introduce the tool that enables it.
What is dbt (data build tool)?
dbt (data build tool) is a data transformation tool that enables teams to model and transform data directly in the data warehouse using SQL. It also introduces a structured approach to analytics engineering, with practices such as version control, testing, and documentation.
Transformations are organized into modular models with defined dependencies, making data pipelines more transparent and maintainable. dbt also provides built-in support for testing, documentation, and data contracts, helping teams ensure data quality and consistency.
This makes it a strong foundation for structuring the Silver layer, where centralized standards and decentralized contributions need to coexist. Below we look in more detail at the key functionalities that support a hybrid approach:
1. Modular modelling
The principle of building models in dbt is splitting transformations into small, reusable blocks, that are easier to understand than a lengthy “spaghetti code”. This also enables clear division of responsibilities, providing consistency, without limiting flexibility:
• Centralized models can handle deduplication, standardization (e.g. date formats) core entities (e.g. users, customers)
• Decentralized models can be built on top handling specific logic such as financial reporting rules or product engagement metrics.
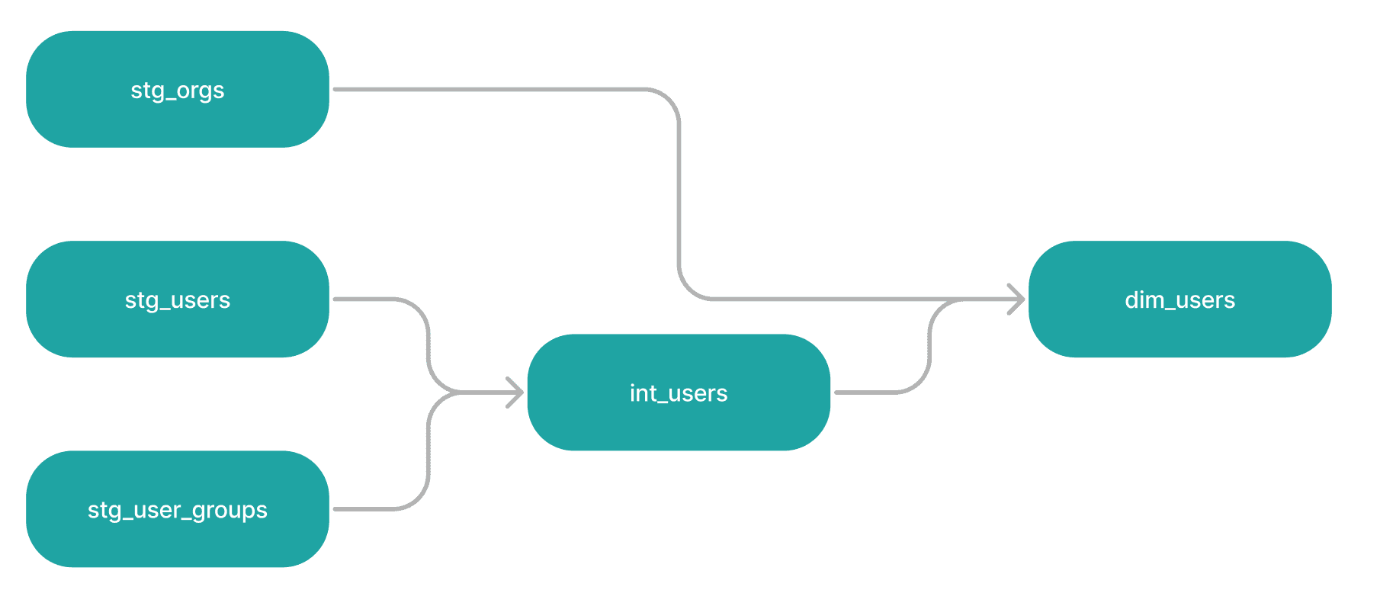
2. Clear dependency visualization
One of dbt’s key features is automatically building DAGs (Directed Acyclic Graphs), that showcase dependencies and relationships between the modules. This facilitates swift collaboration across teams and increases transparency of data flows. There is no wall between data teams: the central team can maintain upstream models, while domain teams can have full visibility and can safely extend them further.
3. Testing and contracts
We all know how important testing is, yet we rarely do it enough. dbt comes with basic out-of-the box checks like uniqueness and nulls validations, but also enables writing custom tests as easily as writing a sql query.
While tests validate the content of the model after it’s build, dbt offers functionality to enforce validation one step earlier - before the build. Thanks to contracts, the central team can define guarantees that must be met in order for the model to be built in the first place. Examples include required columns or fields that must be unique.
4. Documentation
Documentation is another area, alongside tests, that is often underutilized. Everyone agrees on its importance, yet in practice there is rarely enough time for thorough documentation. dbt supports this with auto-generated documentation, including model descriptions, lineage graphs and column-level metadata. When working across multiple teams, this becomes a critical interface for collaboration.
5. Project structure
Code in dbt is managed as files within a folder structure, making it easy to define working areas for both central and domain teams. A common approach is to create a folder for core logic and separate domain folders for each team. This enables clear ownership, well-defined boundaries without building walls, logical structure and easier onboarding of new team members.
Practical Guidelines
While the task is not easy, a few concepts can serve as helpful guidelines:
1. A model is a complete product - It needs to be stable and documented
2. Avoid hidden logic - If a query can be reused, push it upstream
3. Define ownership and purpose – lack of clarity leads to inconsistency
4. Accept some level of duplication – domain-specific definitions might vary
5. Governance over gatekeeping – automated tests and standards scale better than manual reviews and bottlenecks
Putting theory to practice
Take a customer data model. In a hybrid setup, the project folder structure makes ownership visible at a glance:
models/
core/ ← owned by the central data team
stg_customers.sql
dim_customer.sql ← the canonical customer entity
marketing/ ← owned by the marketing team
customer_campaign.sql
customer_consent.sql
finance/ ← owned by the finance team
customer_invoice.sqlFinal Thoughts
The hybrid Silver layer isn't a compromise between centralization and decentralization. It's a different question: which decisions belong to whom? Definitions, contracts, and the canonical entities belong to the central team. Domain logic, business rules, and the metrics that change with strategy belong to the domains.
The reason this matters at Silver, not Gold, is that the alternative is paying for the same disagreement twice, once when central teams interpret raw data without domain context, and again when domain teams rebuild that interpretation downstream. Pushing the boundary earlier removes the duplicated work.
dbt is what makes the boundary maintainable: ownership is visible in the folder structure, contracts make it enforceable, lineage makes it auditable. Without those, the hybrid model becomes a coordination problem. With them, it becomes a design choice.
Keep reading
Eager to learn more? No worries: we’ve got you covered.
.png)
Data Products Need Funding. Not Projects.
Your data product strategy is not failing because of your technology. It is not failing because of your talent. It is hitting a wall because you are trying to run a product organisation on a project budget. These two models are fundamentally incompatible.


From Messy Documents to Governed Knowledge: What Our Hackathon Revealed About AI Agents
Most of an organization's knowledge lives outside structured systems: slide decks, meeting notes, contracts, feedback forms, and old project folders. This knowledge was the focus of a recent Datashift hackathon.

.png)
Centralized or Decentralized? Building a Silver Layer that does both with dbt
Most data teams are stuck choosing between consistency and speed: central control brings governance but creates bottlenecks, while domain ownership brings agility but leads to chaos. This blog explores a hybrid Silver layer that delivers both, using dbt as the framework to make it work.


