Accelerating Spark Notebook Development with MSSparkUtils for Microsoft Fabric
20 February 2024

In the dynamic landscape of big data processing, Apache Spark has emerged as a powerful and versatile framework. Leveraging its capabilities on Microsoft Fabric, Microsoft has introduced MSSparkUtils, a collection of utilities designed to enhance and streamline data processing workflows with Spark for Microsoft Fabric. In this technical blog post, we will explore the key features and benefits of MSSparkUtils, and how it can be effectively utilized to accelerate working with Spark on Azure Fabric.
What is MSSparkUtils?
MSSparkUtils is a set of utilities and enhancements built on top of Apache Spark, tailored specifically for Azure Fabric. It is a built-in package to help you with common tasks such as working with file systems, working with secrets and chaining notebooks together. The package is available in PySpark, Scala, SparkR and Fabric pipelines.
MSSparkUtils is also available in Azure Synapse notebooks. The version for Fabric however contains more features.
Key Features unveiled
1. File System Utilities in MSSparkUtils
Harness the power of mssparkutils.fs to manipulate and glean insights from file systems like Azure Data Lake Storage and Azure Blob Storage effortlessly. From file movement to folder creation or removal, these functions streamline your data handling processes, amplifying efficiency with each operation.
Use mssparkutils.fs.help() to get a list of all available functions.
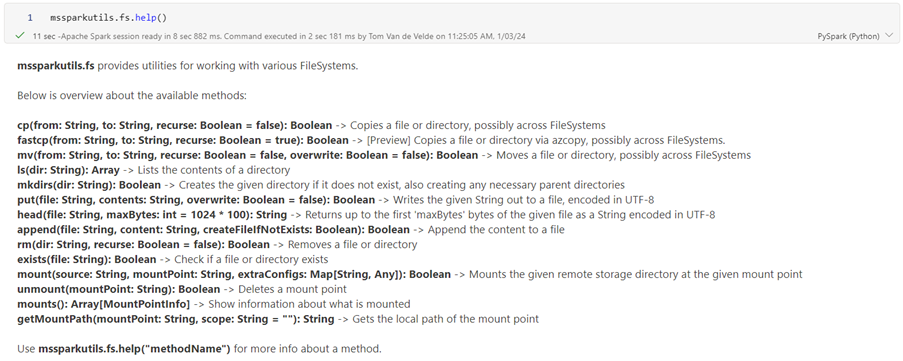
Mounting is making an external file system accessible and usable in the context of your notebook. Once mounted, the files or folders on the external file system become accessible through the specified mount point. This feature is new in the Fabric version MSSparkUtils.
The advantage of using a mount point is that your spark code becomes much cleaner instead of using the external location URL in each function call.
2. Notebook Utilities in MSSparkUtils
The functions in mssparkutils.notebook allow you to chain notebook executions together. It is also possible to pass through variables using the exit values of the notebooks. New for the Fabric version of the MSSparkUtils is the runMultiple function to execute notebooks in parallel. The degree of parallelism is restricted to the total available compute resource of a Spark session.
This package was often used in Synapse notebooks to run several notebooks one after the other. The execution of the notebooks was a lot quicker than scheduling the individual notebooks in a Synapse pipeline. The later had to restart a cluster for each notebook that took a few minutes.
In Fabric compute clusters start up really fast. So the question is if the use case still counts. What would be the fastest in Fabric using the trial capacity?
- Running 4 exactly the same notebooks one after the other from a pipeline

- Running 1 notebook that runs all 4 notebooks after each other


As you can see, using the run statements is still faster. If performance is very important, consider using the notebook library to code your notebook chain.
Use mssparkutils.notebook.help() to get a list of all available functions.

3. Credential Utitlities in MSSparkUtils
mssparkutils.credentials provides you with a set of functions to get access tokens and secrets from an Azure Keyvault. Storing tokens and secrets in clear text in your notebooks is not very secure. So whenever you use a token or a secret, it is best to use this package.
Although the support for Azure Key Vault is on the roadmap for Q1 2024 you can already use the getSecret function which contacts a key vault to get a secret. It will use your own MS Entra ID to authenticate against the key vault, even if you schedule a pipeline that executes a notebook that contains this function.
Getting a token requires you to enter an audience key. The following list shows the currently available audience keys:
- Storage Audience Resource: "storage"
- Power BI Resource: "pbi"
- Azure Key Vault Resource: "keyvault"
- Synapse RTA KQL DB Resource: "kusto"
Use mssparkutils.credentials.help() to get a list of all available functions.

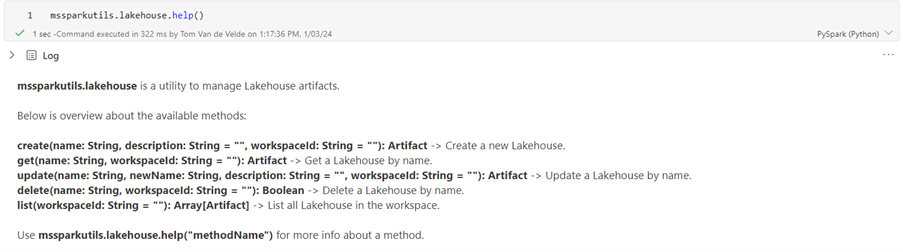
4. Lakehouse Utilities in MSSparkUtils
This package is already available, but it is not yet documented by Microsoft on the MSSparkUtils documentation page.
Using these functions you can manage lakehouse artifacts. Functions exist to create, update and delete lakehouses in Fabric. A potential use case would be to automatically create a lakehouse(with SQL endpoint and semantic model) when it doesn’t exist already. Please keep in mind that since this functionality is not documented, it probably still is preview and may change.
Use mssparkutils.lakehouse.help() to get a list of all available functions.
Getting Started with MSSparkUtils for Microsoft Fabric
To start using MSSparkUtils for Microsoft Fabric, you don’t have to install anything. The library is automatically installed on the Spark clusters. Even importing the library is not necessary. However the documentation states that importing the library is necessary when it is not available…
If you want to integrate with other Azure services, you will have to configure authentication and authorization settings first. In the Azure Synapse version of the MSSparkUtils documentation there’s a whole chapter on how to connect to storage accounts or access to key vaults. In the Fabric version, this is only handled when using mounts where you can use an account key or a sas token to authenticate. This will probably be the suggested way of working. First create mount points and then use the fs library.
On the roadmap for Q1 there’s the availability of managed identities. It will be possible to configure managed identities on workspace level. If that is available it will probably be possible to grant the managed identity of the workspace access to the Key Vault instead of always using a personal account.
Conclusion
MSSparkUtils for Microsoft Fabric allows data engineers, data scientists, and developers to use the full potential of Apache Spark within the Azure ecosystem. By providing a set of tailored utilities, MSSparkUtils accelerates working with Apache Spark. Chaining notebooks with this library still is faster than scheduling them in a pipeline although the difference is a lot less than when chaining notebooks in Azure Synapse.
Want more information on how to create value with Microsoft Fabric? Contact us or follow our webinar at the end of this month.
